Courses: Introduction to GoldSim:
Unit 12 - Probabilistic Simulation: Part I
Lesson 7 - Viewing Time Histories of Probabilistic Results
In the previous Lesson we discussed a very simple example of Monte Carlo simulation in GoldSim by showing how you would simulate rolling two dice. We explored how you would view a distribution output (in this case, the distribution of the outcome of rolling the two dice).
This example was particularly simplistic because it was static; that is, nothing was changing with time. However, almost every model you will want to build will be dynamic (variables will change with time and you will represent these dynamics using the features and capabilities we have started to discuss in the first 10 Units). When we ran a static model 100,000 times, the output consisted of the result of 100,000 dice rolls (one for each realization). However, recall that in a dynamic simulation, the output consists of a time history of values (a value at each timestep) for every result. So for a probabilistic dynamic simulation, the outputs consists of a time history of values for every result for every realization. Hence, if we run 100,000 realizations, we would have 100,000 time histories for every result. How do we display and interpret so much information? This Lesson discusses that.
To do so, we will examine another Example model. Go to the “Examples” subfolder of the “Basic GoldSim Course” folder you should have downloaded and unzipped to your Desktop, and open a model file named Example20_UncertainEvaporation.gsm. This is a model of an evaporating pond that, with two exceptions, is identical to a model you have already built (Exercise 8 in Unit 8, Lesson 6). The model looks like this:
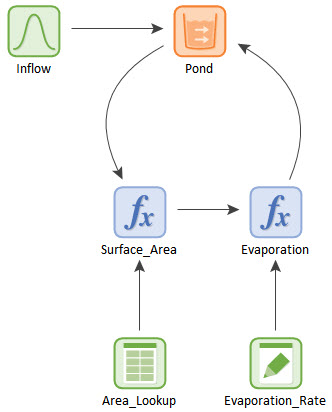
In Exercise 8, the Inflow was defined as a Data element (equal to 10 m3/day). In this Example, the Inflow is defined as a probability distribution. If you double-click on it, and then press the Edit… button, you will see that the Inflow is specified as a Truncated Normal distribution:
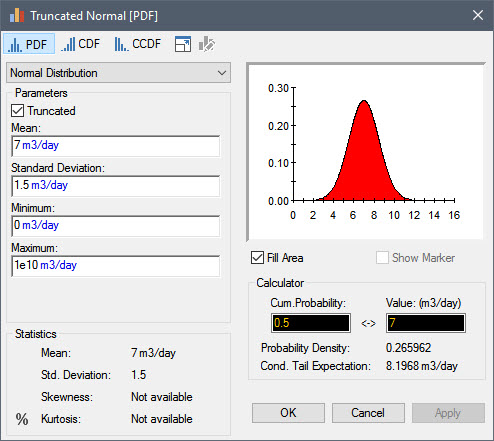
The distribution has a Mean of 7 m3/day and a Standard Deviation of 1.5 m3/day. A normal distribution asymptotically approaches (i.e., never reaches) a probability density of zero on both sides. Hence, here it is truncated (assigned Minimum and Maximum values), because we want to ensure that a negative value can never be sampled (as this would not make sense physically). Although without truncation, the probability of a negative value is small, it is not zero. The Maximum is simply set to a very large number (so it has no effective impact).
What we are stating here is that the Inflow will be constant in time (we know this because the Mode is specified on the main dialog as “Sampled once”), but we are uncertain (due to lack of knowledge) what the value for the Inflow will be. We believe that the most likely value for the Inflow is 7 m3/day, and there is about a 68% chance that it will be between 5.5 m3/day and 8.5 m3/day (i.e., within one standard deviation), and about a 95% chance that it will be between 4 m3/day and 10 m3/day (i.e., within two standard deviations).
The second change from Exercise 8 is in the Simulation Settings dialog. If you look at the Simulation Settings (the Monte Carlo tab), you will note that the model is specified to run for 1000 realizations (instead of 1).
Run the model now. After doing so, right-click on the element named Evaporation and select Time History Result… to plot the time history of the rate of evaporation from the pond. You will see the following dialog displayed:
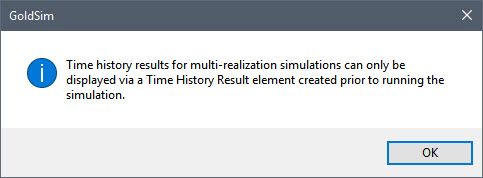
This is the first thing that you must understand about probabilistic time history results. Whereas when running a deterministic simulation (i.e., a single realization) you can right-click on any element and plot its time history, when running a probabilistic simulation (i.e., multiple realizations) you can no longer do so. For multi-realization simulations, time history results can only be displayed using a Time History Result element that was created prior to running the simulation. That is, you can only plot time histories for elements that you have specifically indicated that you want to save and view. This is because for realistic models (with hundreds or thousands of elements), saving time history results for all elements and all realizations could potentially require a very large amount of memory (and disk space if you were to save the model). Hence, GoldSim only saves time histories for results that you are specifically interested in viewing.
Note: Time History Result elements were discussed in detail in Unit 6, Lesson 12.
In this simple model, we do in fact have a Time History Result element. It is named “Results” and is set up to plot the pond volume (i.e., the primary output of the Pond element). Double-click on it now:
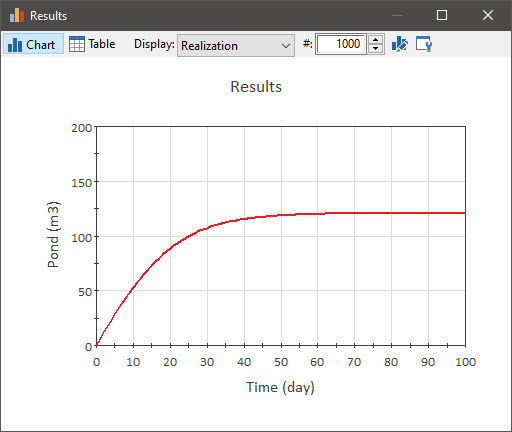
When viewing probabilistic time histories, GoldSim provides a number of different ways to view the results (controlled by the Display drop-list).
In the plot above, we are simply viewing one realization at a time. In the plot shown above, we are viewing Realization # 1000. Note, however, that the dialog includes a spin control that we can use to view any of the 1000 realizations (by stepping through each one, or by entering a number directly):

The Display drop-list provides several other options for displaying the results. The second option in the list is “All Realizations”:
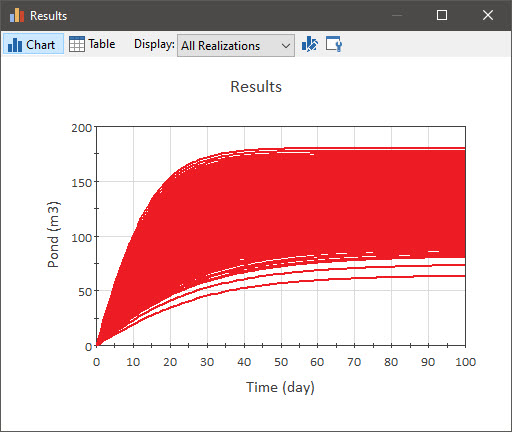
This plot shows all 1000 realizations. It is a bit messy because we have so many realizations (and hence many of the lines overlap).
Note: As an aside, it is worth pointing out here that different realizations should not be thought of as different “scenarios”. As we shall see in a subsequent Unit, GoldSim provides very powerful tools for creating and displaying scenarios. In GoldSim, multiple scenarios can be created within a model to represent different sets of input assumptions. That is, scenarios are differentiated by having different sets of input data. That is not the case for realizations. Each realization uses the same set of input data; they just represent different possible “futures” given our uncertainties in those inputs.
An alternative way for displaying multiple realizations is to show probability histories (by selecting “Probabilities” from the Display drop-list):
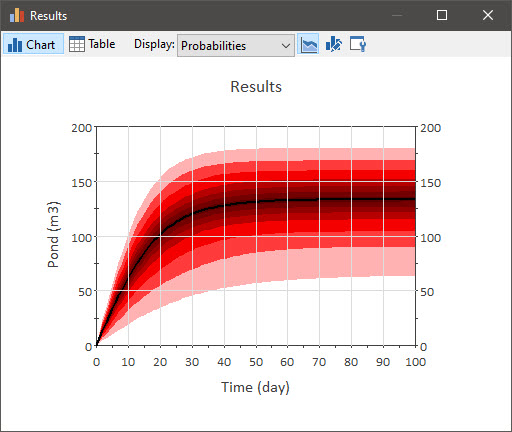
In a probability histories display, multiple realizations are represented by displaying the percentiles (as well as the bounds and the mean) of the set of time histories. If you place your cursor anywhere in the chart, a tool-tip will display the percentile range associated with that location:
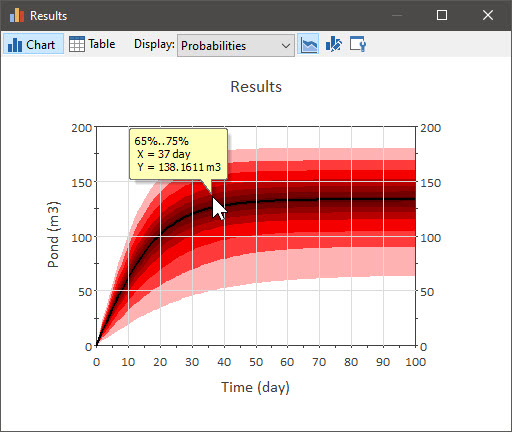
The legend will also display the various ranges. You can turn on and off the legend by right-clicking in the chart and selecting View | Show Legend:
Note that the statistics that are displayed can be customized. If you are interested, you can read about how to do so in GoldSim Help.
You can also view a single statistic at a time by selecting “Statistic” from the Display drop-list. You can then use the drop-list immediately to the right to select the statistic to be displayed:
For each of these various displays, you can also view a table of results by pressing the Table button:
- When viewing a single “Realization” or “Statistic”, a single time history is displayed in the table.
- When viewing “All Realizations”, each realization is displayed in a separate column.
- When viewing “Probabilities”, each statistic is displayed in a separate column.
Of course, you can still view distribution results in a dynamic probabilistic simulation. Let’s do that now by right-clicking on the Pond element and selecting Distribution Result… :
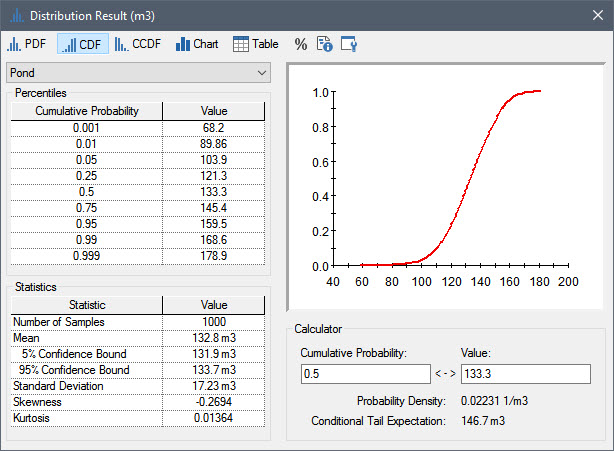
So what is this showing? It is the distribution of the final value of the pond volume. If you refer back to the probability history shown previously, this is essentially a vertical “slice” through that plot at an elapsed time of 100 days.
Note: As we will discuss in the next Unit, you can also view such distributions at other “time slices” (i.e., not just at the end of the simulation).